Elasticsearch概述
Elasticsearch是一个开源的分布式搜索和分析引擎,广泛应用于全文搜索、日志分析、实时数据处理等领域。它基于Apache Lucene构建,具有高效的查询、存储和分析能力,能够处理海量数据。
Elasticsearch采用了RESTful API作为与外部系统交互的方式,使得用户可以通过简单的HTTP请求进行操作。
Elasticsearch的基础概念

索引(Index)
索引是Elasticsearch中的基本数据单元,相当于关系数据库中的数据库。在Elasticsearch中,索引是用来组织数据的容器,它包含了多份数据和配置。每个索引都有一个独立的配置和映射,允许用户自定义字段的类型、分析方式等。
文档(Document)
文档是Elasticsearch中的基本数据存储单元,相当于关系型数据库中的行。每个文档包含一组字段(Field),这些字段描述了文档的各种信息。文档是以 JSON格式进行存储的,可以通过唯一的ID来标识。
映射(Mapping)
映射定义了文档中字段的结构和数据类型。类似于关系型数据库中的表结构定义,定义Elasticsearch如何存储和索引数据。
集群(Cluster)
Elasticsearch集群由多个节点(Node)组成。每个集群有一个唯一的名字,多个节点共同工作,分担数据存储、索引、查询等任务。
分片与副本(Shard & Replica)
每个索引在内部会被分割成多个分片(Shard),而每个分片可以有多个副本(Replica)。分片允许数据分布在多个节点上,而副本提高了数据的可用性与查询性能。
Elasticsearch的底层结构
Elasticsearch的底层实现依赖于倒排索引(Inverted Index)机制,这种索引结构在搜索引擎中是非常常见的。倒排索引的核心思想是记录文档中每个词项(Term)出现的位置,从而可以快速检索包含特定词项的文档。
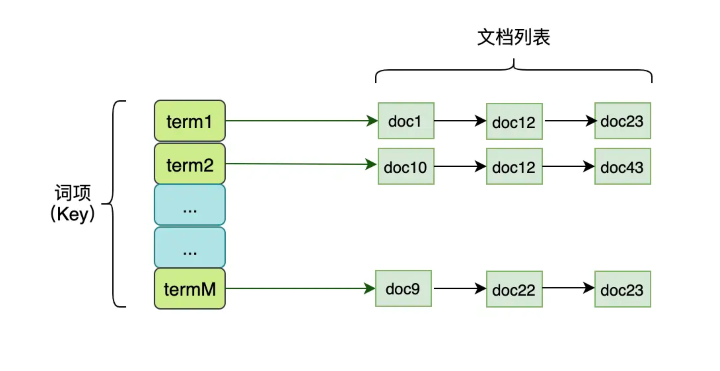
倒排索引的基本构建过程如下:首先Elasticsearch将字段中的文本分解为多个词项,对于文本字段,Elasticsearch会使用分词器(Analyzer)将文本拆分为一个个词项(Term);然后对于每个词项,Elasticsearch会记录它在所有文档中的出现位置(文档ID),这种方式的优点是当查询某个词项时,能够非常高效地找到包含该词项的文档。
Elasticsearch的查询流程
- 请求路由:查询请求会根据索引与分片策略确定查询的目标分片。Elasticsearch使用路由策略(默认是哈希路由)将请求发送至合适的分片。
- 执行查询:一旦请求被路由到目标分片,所有分片会并行执行查询。每个分片是一个独立的Lucene实例,所以查询将在每个分片内执行,Lucene会利用倒排索引进行高效查询。
- 聚合与排序:对于涉及聚合与排序的查询,Elasticsearch会首先执行这些操作,合并各个分片的结果,然后返回最终结果。
- 合并与返回:所有分片的查询结果会合并,并且如果涉及排序或分页,Elasticsearch会在合并结果的基础上执行排序和分页操作。