消息队列Kafka概述
Kafka是由LinkedIn公司开发的一款分布式的流数据处理系统,它是一个高可靠、高吞吐量、低延迟的分布式发布订阅消息系统。Kafka最初是为解决LinkedIn的大规模实时数据处理需求而设计的,后来被Apache基金会接收并成为一个开源项目。
Kafka的设计目标是能够处理大量的数据流,支持数百万的消息/秒,具有高可用性和可伸缩性。Kafka提供了许多功能,包括持久化消息、分布式消息发布和订阅、多副本备份、数据压缩、流数据处理等。
消息队列的通信模式
点对点模式
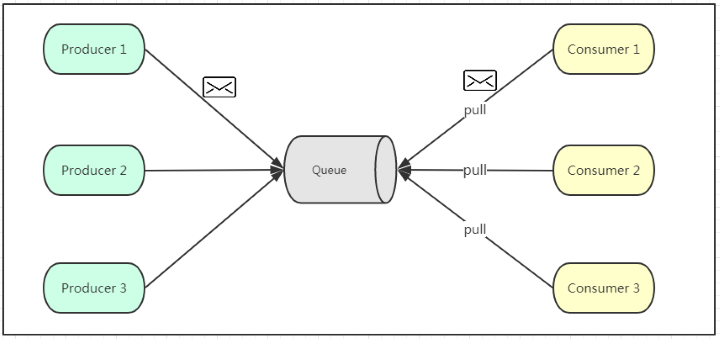
点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制,但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
发布订阅模式
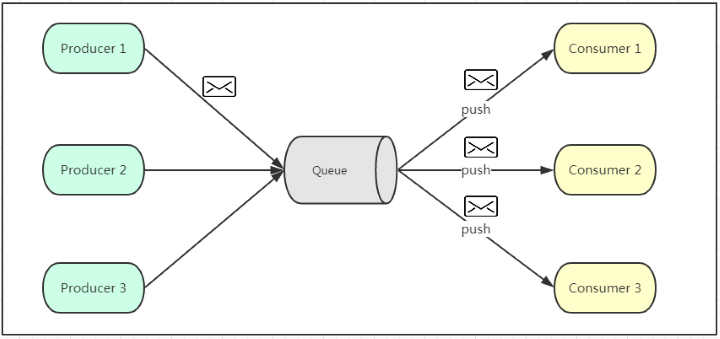
发布订阅模式是一个基于消息送的消息传送模型,该模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息。
Kafka集群的基础架构
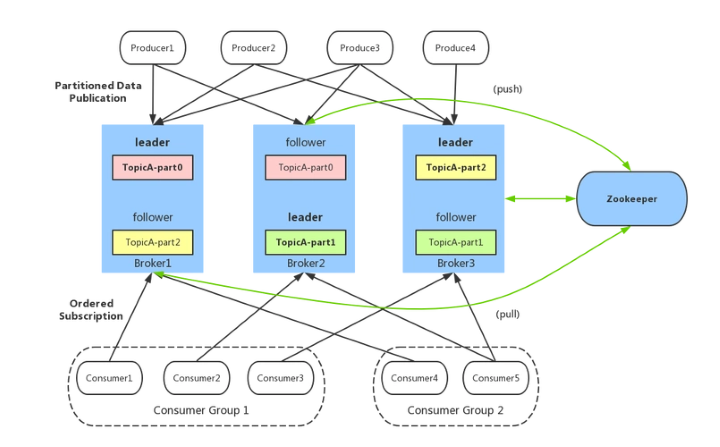
- Producer:消息生产者。发布消息到kafka集群的终端或服务。
- Consumer:消息消费者。从kafka集群中消费消息的终端或服务。
- Consumer group:消费者组。每个consumer都属于一个consumer group,一个partition只能被同一个consumer group中的一个consumer 消费,但可以被多个不同consumer group中的consumer消费。
- Broker:集群中的每一个kafka进程都是一个Broker,通常一台服务器上部署一个broker。
- Topic:主题。每条发布到 kafka 集群的消息属于的类别,即kafka是面向topic的,topic是逻辑概念。
- Partition:分区。每个topic包含一个或多个partition。kafka分配的单位是partition,partition是物理概念,生产者发送的消息就是保存在partition中的。
- Segment:partition物理上由多个segment组成。
- offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续递增的序列号叫做offset,偏移量offset在每个分区中是唯一的。
- replica:partition的副本,保障partition的高可用,leader和follower统称为Replica。在kafka集群中,为了防止数据丢失,每个partition一般都会有一个主分区和一至多个从分区,当然也可以有且只有一个主分区。
- leader:replica中的一个角色,主分区所在的节点称为leader。在kafka集群中,每个partition都有一个leader,producer和consumer只跟leader交互,leader负责数据的读写。
- follower:replica中的一个角色,从分区所在的节点称为follower,follower从leader中复制数据。为了防止leader与follower节点上数据不一致性的问题,kafka没有使用读写分离,而是只在leader节点上读写数据,follower节点只是从leader节点上定期复制数据。
- controller:kafka 集群中的一个broker,用来进行leader选举以及各种故障转移。
- zookeeper:kafka通过zookeeper来存储集群的基本信息,主要包括kafka的broker列表、topic和partition等信息。