grep命令简介
grep的全称是global regular expression print,即全局正则表达式打印。它的核心功能是在文件中搜索特定模式的文本,并将包含该模式的行打印出来。grep支持强大的正则表达式语法,这使得它能够灵活匹配各种复杂的文本模式 。
基本用法详解
命令格式
grep [选项] 搜索内容 文件或目录
选项列表
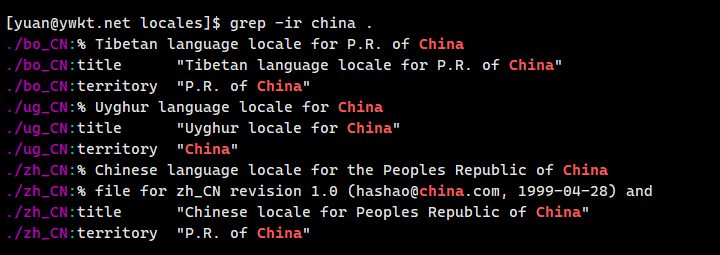
- −i: 搜索时忽略英文大小写。
- −n: 在搜索结果前显示行号。
- −c: 只显示匹配行数,不显示搜索结果。
- −r:在目录中递归搜索内容。
- −l:只显示文件名称。
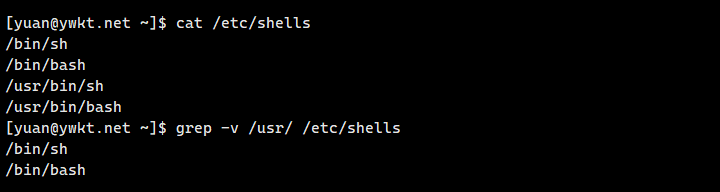
- −v:反向搜索,搜索不包含指定内容的行。
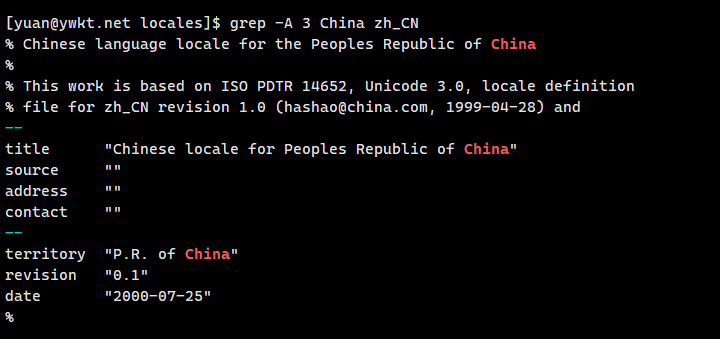
- −A n:显示搜索结果及后n行内容。
- −B n:显示搜索结果及前n行内容。
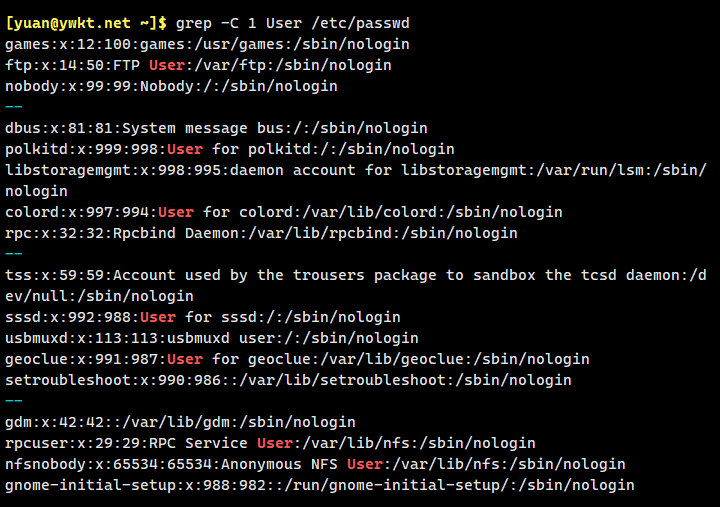
- −C n:显示搜索结果及前后n行内容。
使用示例
1、grep −i 搜索内容 文件:在文件中搜索指定内容,忽略英文大小写。

2、grep −n 搜索内容 文件:在文件中搜索指定内容,并在搜索结果前显示行号。

3、grep −v 搜索内容 文件:反向搜索,搜索不包含指定内容的文本行。
4、grep −r 搜索内容 目录:在目录及子目录的文件中递归搜索指定内容。
5、grep −l 搜索内容 目录:在目录内的文件中搜索指定内容,但只显示包含内容的文件名称。

6、grep −A n 搜索内容 文件:在文件中搜索指定内容,并显示搜索结果及后n行的内容。
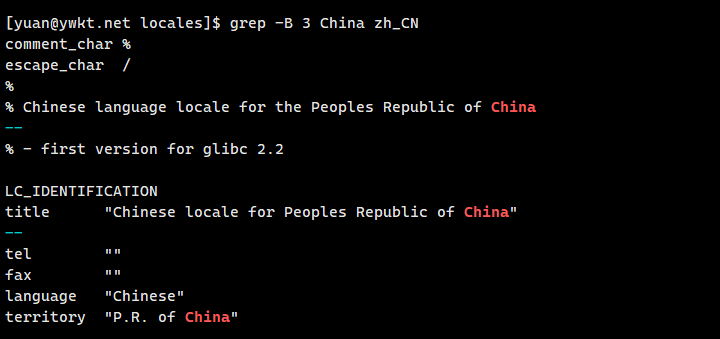
7、grep −B n 搜索内容 文件:在文件中搜索指定内容,并显示搜索结果及前n行的内容。
8、grep −C n 搜索内容 文件:在文件中搜索指定内容,并显示搜索结果及前后n行的内容。